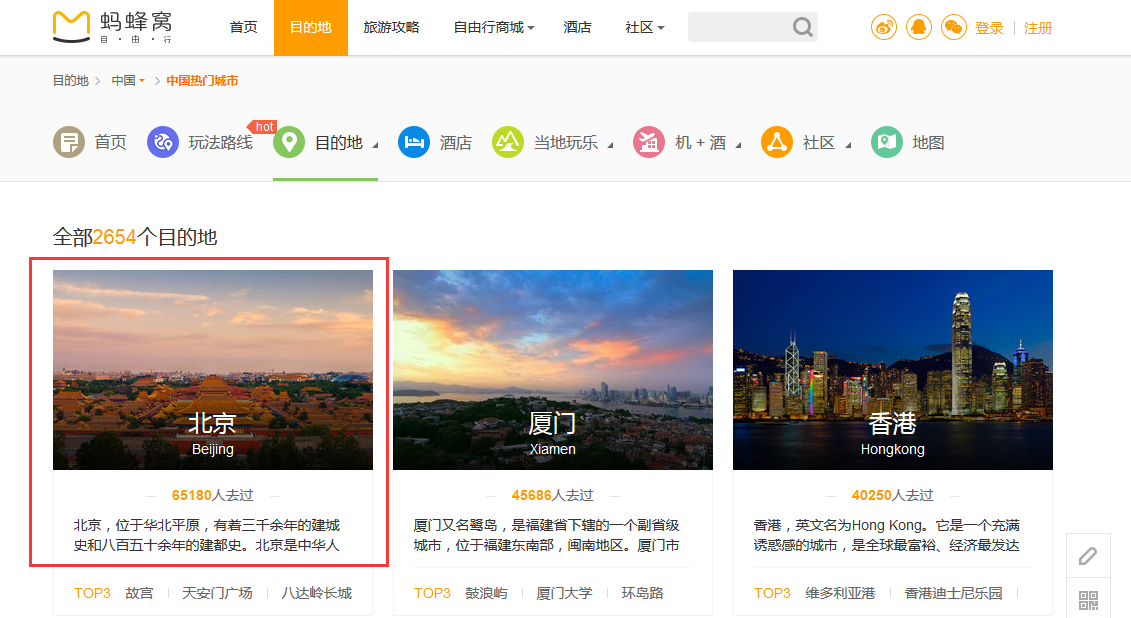
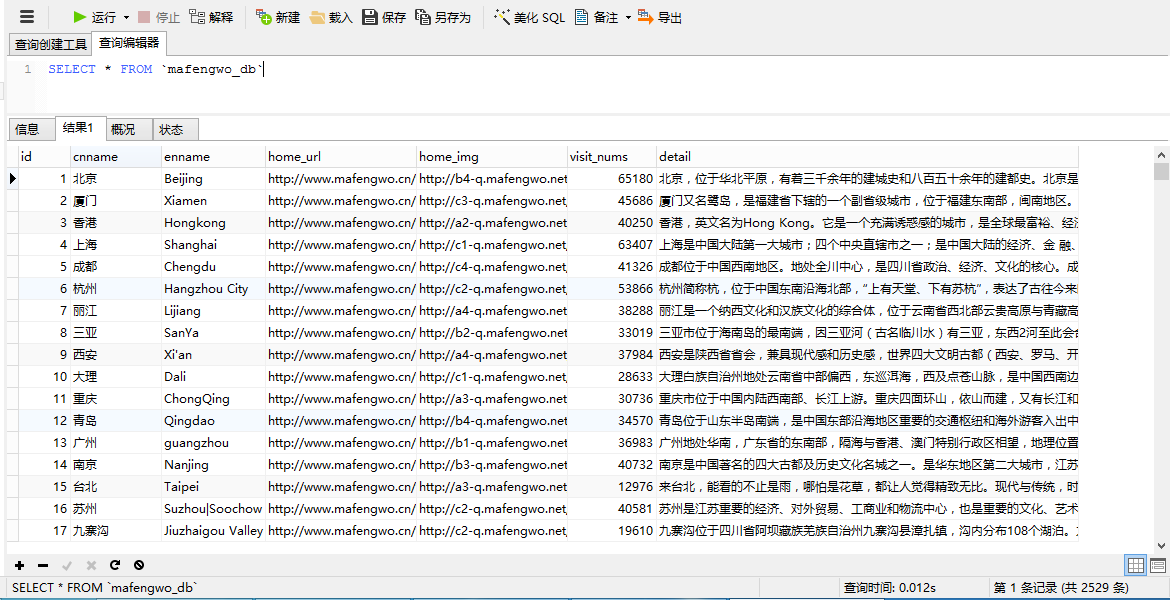
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
"""
Created on Sat Oct 22 18:28:26 2016
@author: bgods
"""
import MySQLdb
import requests
import json
from lxml import etree
class MafengwoSpider:
def __init__(self,con):
self.con = con
self.page = 1
self.url = 'http://www.mafengwo.cn/mdd/base/list/pagedata_citylist'
self.headers = {
'Host': 'www.mafengwo.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'http://www.mafengwo.cn/mdd/citylist/21536.html',
'Content-Length': '20',
'Connection': 'keep-alive'
}
def GetPage(self):
data = {"mddid" : "21536", "page" : self.page}
html = requests.post(url=self.url, data=data, headers=self.headers)
html = json.loads(html.text)
lists = etree.HTML(html['list'])
L = lists.xpath('//li')
data = []
for l in L:
l = etree.HTML(etree.tostring(l))
home_url = l.xpath('//div[@class="img"]/a/@href')
home_img = l.xpath('//li/div/a/img/@data-original')
cnname = l.xpath('//div[@class="title"]/text()[1]')
enname = l.xpath('//p[@class="enname"]/text()')
visit_nums = l.xpath('//div[@class="nums"]/b/text()')
detail = l.xpath('//div[@class="detail"]/text()')
d = {}
d["home_url"] = self.d(home_url).strip()
d["home_img"] = self.d(home_img).strip()
d["cnname"] = self.d(cnname).strip()
d["enname"] = self.d(enname).strip()
d["visit_nums"] = self.d(visit_nums).strip()
d["detail"] = self.d(detail).strip()
data.append(d)
for d in data:
self.write_sql(d)
pages = etree.HTML(html['page'])
print "Start crawling the page:",pages.xpath('//span[@class="pg-current"]//text()')[0]
if len(pages.xpath('//a[@class="pg-next _j_pageitem"]//text()'))==0:
print("Crawl finished......")
else:
self.page += 1
return self.GetPage()
def d(self,data):
if len(data)==0:
return ''
else:
return data[0]
def write_sql(self,data):
d = ('http://www.mafengwo.cn' + data["home_url"].encode('utf8'),
data["home_img"].encode('utf8'),
data["cnname"].encode('utf8'),
data["enname"].encode('utf8'),
data["visit_nums"].encode('utf8'),
data["detail"].encode('utf8')
)
sql = 'INSERT INTO Mafengwo_db (home_url,home_img,cnname,enname,visit_nums,detail) ' \
'VALUES ("%s", "%s", "%s", "%s", "%s", "%s");' % d
try:
self.con.execute(sql)
print sql
except:
pass
if __name__ == '__main__':
db = MySQLdb.connect("localhost", "root", "root", "spider", charset='utf8') con = db.cursor()
Mafengwo = MafengwoSpider(con)
Mafengwo.GetPage()
db.close()
|