接触爬虫也有一段时间了,起初都是使用request库爬取数据,并没有使用过什么爬虫框架。对于scrapy这个框架,之前仅仅是好奇,这两天看了一下scrapy文档,也试着去爬了一些数据,发现还是很方便的。
以下以爬 易车网的销售指数为例。
要爬取的字段是:
- 时间(年月);
- 分类类别(包括小型、微型、中型、紧凑型、中大型、SUV、MPV);
- 车型(二级分类);
- 销量。
分析网站结构
首先分析网站结构,其中包括翻页的实现、不同类别、数据的加载类型(aspx或者html)、请求类型(post、get)等等。
静态方式
- 通过点击翻页按钮,发现URL是改变的,比如紧凑型车2016-3第二个页面的URL是:
- http://index.bitauto.com/xiaoliang/jincouxingche/2016m3/2/;
- 以上URL红色部分的2016是年份,3是月份,2是页码,jincouxingche是表示紧凑型车;
- 如果需要查询季度数据,只需要把url中的m改为s就行,比如“2016s2”表示查询2016年第二季度数据;
- 所以我们只需要改变URL中的年份、月份、页码、类别,就可以请求到不同的数据。
动态方式
再深入我们发现,点击页面中的切换时间按钮(javascript实现)时,发现url是没有发生改变的,返回的是aspx页面。
使用抓包工具(我使用的是火狐自带的)可以查看URL是什么,提交了什么数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# URL
URL = "http://index.bitauto.com/Interface/GetData.aspx?"
# 提交参数
data = {
"indexType": "xiaoliang",
"brandType": "level",
"itemID": "0",
"dateType": "m", # 日期类型(月份m,季度s)
"dateValue": "1", # 月份(1-12)、季度(1-4)
"cityID": "0", # 城市代码,0代表是全国。
"dateYear": "2016", # 年份
"pageBlock": "indexListMore",
"levelSpell": "jincouxingche", # 分类类别
"0.418664796167437": ""
}
# 改变字典data中dateType、dateValue、dateYear、levelSpell的值,就可以请求到不同的数据。
关于城市代码可以通过抓包获取到,这里是我用抓包工具获取到地址。
当然这种方式,可以查询更多的纬度数据;但是有个问题,目前我没有找到哪个参数是实现翻页的。所以这里使用的是第一种方式获取数据。
编写spiders
yicheSpider.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54# -*- coding:utf-8 -*-
import scrapy
from scrapy.http import Request
from yiche.items import YicheItem
import re
# create UrlList
url_list = []
Type = ['jincouxingche','xiaoxingche','weixingche','zhongxingche','zhongdaxingche','suv','mpv']
for t in Type:
for year in range(2010,2016):
for m in range(1,13):
url = 'http://index.bitauto.com/xiaoliang/'+t+'/'+str(year)+'m'+str(m)+'/1'
url_list.append(url)
class YicheSpider(scrapy.spiders.Spider):
name = "yiche"
allowed_domains = ["index.bitauto.com"]
start_urls = url_list
def parse(self, response):
# 获取第一个页面的数据
s = response.url
t,year,m = re.findall('xiaoliang/(.*?)/(\d+)m(\d+)',s,re.S)[0]
for sel in response.xpath('//ol/li'):
Name = sel.xpath('a/text()').extract()[0]
SalesNum = sel.xpath('span/text()').extract()[0]
#print Name,SalesNum
items = YicheItem()
items['Date'] = str(year)+'/'+str(m)
items['CarName'] = Name
items['Type'] = t
items['SalesNum'] = SalesNum
yield items
# 判断是否还有下一页,如果没有跳过,有则爬取下一个页面
if len(response.xpath('//div[@class="the_pages"]/@class').extract())==0:
pass
else:
next_pageclass = response.xpath('//div[@class="the_pages"]/div/span[@class="next_off"]/@class').extract()
next_page = response.xpath('//div[@class="the_pages"]/div/span[@class="next_off"]/text()').extract()
if len(next_page)!=0 and len(next_pageclass)!=0:
pass
else:
next_url = 'http://index.bitauto.com'+response.xpath('//div[@class="the_pages"]/div/a/@href')[-1].extract()
yield Request(next_url, callback=self.parse)items.py
1
2
3
4
5
6
7
8
9
10# -*- coding: utf-8 -*-
import scrapy
class YicheItem(scrapy.Item):
# define the fields for your item here like:
Date = scrapy.Field()
CarName = scrapy.Field()
Type = scrapy.Field()
SalesNum = scrapy.Field()
保存到数据库
修改settings.py
1
2
3ITEM_PIPELINES = {
'yiche.pipelines.YichePipeline': 300,
}修改pipeline文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# -*- coding: utf-8 -*-
import MySQLdb
import MySQLdb.cursors
import logging
from twisted.enterprise import adbapi
class YichePipeline(object):
def __init__(self):
self.dbpool = adbapi.ConnectionPool(
dbapiName ='MySQLdb',#数据库类型,我这里是mysql
host ='127.0.0.1',#IP地址,这里是本地
db = 'scrapy',#数据库名称
user = 'root',#用户名
passwd = 'root',#密码
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',#使用编码类型
use_unicode = False
)
# pipeline dafault function
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
logging.debug(query)
return item
# 插入数据到数据库
def _conditional_insert(self, tx, item):
parms = (item['Date'],item['CarName'],item['Type'],item['SalesNum'])
sql = "insert into yiche (Date,CarName,Type,SalesNum) values('%s','%s','%s','%s') " % parms
#logging.debug(sql)
tx.execute(sql)
开始爬取
- 终端执行命令开始爬取
1
scrapy crawl yiche
结束之后,可以看到总共发送701个get请求,状态码是200的有701个,说明每一个都请求成功,当然还有其他日志文件log等等信息。。。
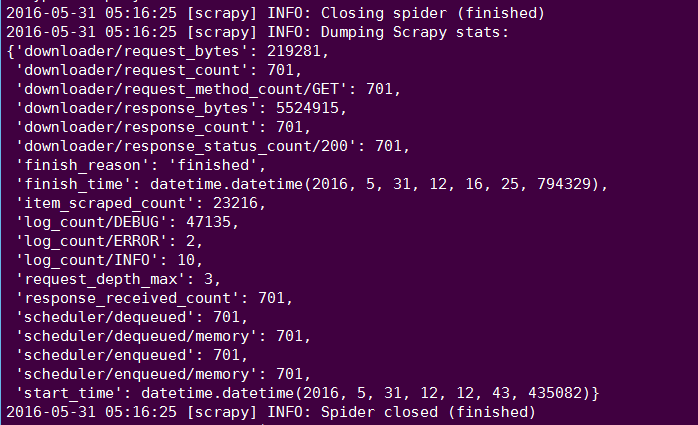
最后,我们再去数据库看都爬了多少数据
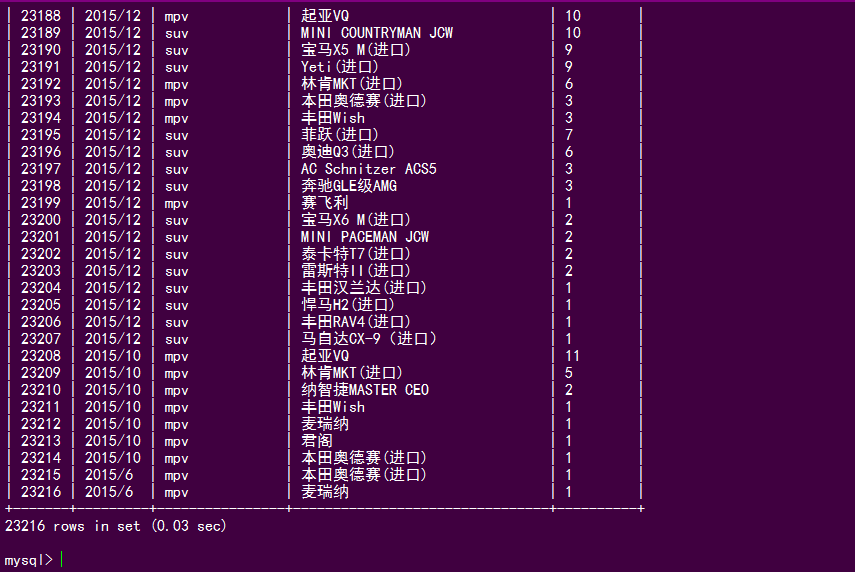
可以看到,数据有大概2W+条记录,和网上对比一下数据还是很完整的。
说明:本文使用的环境是ubuntu+python2.7.11+scrapy1.03