Scrapy框架的数据处理流程是由Scrapy引擎进行控制,它的整体架构如图所示。图中的绿色街头表示数据的流向。
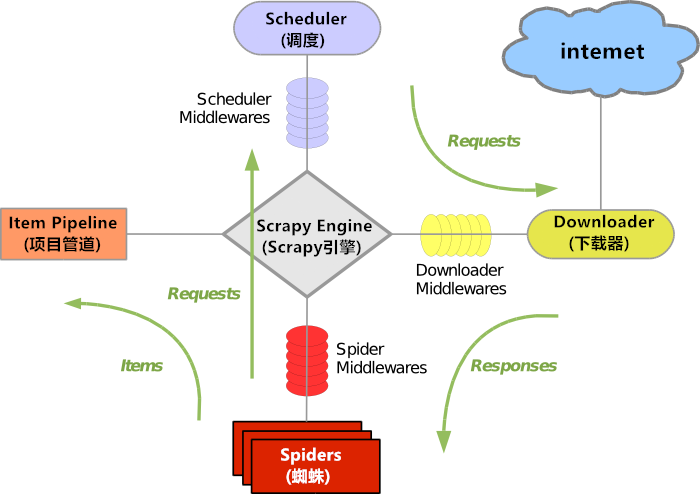
Scrapy 的运行流程为:
- Scrapy 引擎打开一个初始的域名,并定位到相应的蜘蛛处理属于这个域名的 URL,然后 让蜘蛛获取第一个要爬取的 URL;
- Scrapy 引擎从蜘蛛那里获得第一个需要爬取的 URL 并将该 URL 包装成请求并指定响应该 该请求的回调函数,然后将其发送给调度器;
- Scrapy 引擎向调度器请求下一步要进行爬取的页面;
- 调度器将下一个要爬取的 URL 以请求的方式返回给 Scrapy 引擎,Scrapy 引擎通过下载器 中间件将请求发送给下载器;
- 当下载器执行请求、下载完页面以后,下载的页面内容通过下载器中间件发送给 Scrapy 引擎;
- Scrapy 引擎在收到下载器的返回的下载数据后,通过蜘蛛中间件将响应数据发送到蜘蛛 进行数据处理;
- 蜘蛛解析下载的页面并返回网页解析后的数据,然后将抽取出的要继续爬取的 URL 再次 封装成请求发送给 Scrapy 引擎;
- Scrapy 引擎将解析完成的数据发送至数据处理流水线,并将新的 URL 爬取请求继续转发 给调度器;
- 系统重复步骤 2-8,直到调度器中没有新的请求,就会关闭爬虫。
转载自:Scrapy抓取框架的介绍